1. 什么是短链接
顾名思义,短链接即是长度较短的网址。通过短链接技术,我们可以将长度较长的链接压缩成较短的链接。并通过跳转的方式,将用户请求由短链接重定向到长链接上去。短链接主要用在诸如微博,BBS等对帖子字数有限制的网站,通过使用短链接,用户可以把注意力放在帖子的内容上,而不是在担心链接超长的问题。这里以百度的 dwz.cn 短链接服务为例,我们使用百度搜索”hello world”,链接为https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=hello%20world&rsv_pq=8487bffe00068c60&rsv_t=a9e0f5b6haiMQwAi4N2y8PHDv37rM6sjjKrHJb6KdMGg2dQuUjAnmSEnXtE&rqlang=cn&rsv_enter=1&rsv_sug3=10&rsv_sug1=9&rsv_sug7=100,统计了一下,这条链接长度为230。如此长的链接占据微博篇幅不说,也会影响微博的美观度。这个时候我们可以使用百度短链接服务压缩一下上面的长链接,压缩后的链接为:http://dwz.cn/5DDXhH。可以看到,压缩后的链接长度比原链接明显变短了。
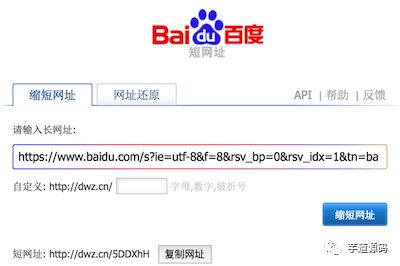
百度短地址服务
2. 常见的短链接压缩算法
常见的短链接压缩算法有两种,第一种是对 URL 进行hash运算,在得到的hash值上做进一步运算,得到一个较短的hash值。第二种是通过数据库自增ID或分布式key-value系统模拟发号器进行发号压缩URL。两种方式各有优劣,hash运算简单易实现,但是有一定的冲突率。随着 URL 压缩数量的增加,冲突数也会增加,最终导致一部分用户跳转到错误的地址上,影响用户体验。而发号器发号压缩 URL 优缺点恰好和hash压缩算法相反,优点是不存在冲突问题。缺点是,实现上稍复杂,要协调发号器取初始号。本文对应的练手项目是基于第二种压缩算法实现的,下面也将对详细分析第二种算法。
3. 使用发号策略压缩URL
发号策略是这样的,当一个新的链接过来时,发号器发一个号与之对应。往后只要有新链接过来,发号器不停发号就好。举个例子,第一个进来的链接发号器发0号,对应的短链接为 xx.xxx/0,第二个进来的链接发号器发1号,对应的短链接为 xx.xxx/1,以此类推。
发号器发出的10进制号需要转换成62进制,这样可以大大缩短号码转换成字符串后的长度。比如发号器发出 10,000,000,000 这个号码,如果不转换成62进制,直接拼接在域名后面,得到这样一个链接 xx.xxx/10000000000。将上面的号码转换成62进制,结果为AOYKUa,长度只有6位,拼接得到的链接为 xx.xxx/AOYKUa。可以看得出,进制转换后得到的短链接长度变短了一些。6位62进制数,对应的号码空间为626,约等于568亿。也就是说发号器可以发568亿个号,这个号码空间应该能够满足多数项目的需求了,所以基本上不用担心发号器无号可发的情况。
上述是发号策略压缩URL的原理,在实际写代码的过程中还需要考虑很多细节,比如缓存,存储等。本文对应的项目基于 Redis 缓存,MySQL 数据库实现了一个简单的分布式短链接服务。代码放到了 Github 上了 -> 分布式短链接项目代码
4. 几个细节问题
Q:同一长链接,每次转成的短链接是否一样
A:同一长链接,每次转成的短链接不一定一样,原因在于如果查询缓存时,如果未命中,发号器会发新号给这个链接。需要说明的是,缓存应该缓存经常转换的热门链接,假设设定缓存过期时间为一小时,如果某个链接很活跃的话,缓存查询命中后,缓存会刷新这个链接的存活时间,重新计时,这个链接就会长久存在缓存中。对于一些生僻链接,从存入缓存开始,在存活时间内很可能不会被再次访问,存活时间结束缓存会删除记录。下一次转换这个生僻链接,缓存不命中,发号器会重新发号。这样一来会导致一条长链接对应多条短链接的情况出现,不仅浪费存储空间,又浪费发号器资源。那么是否有办法解决这个问题呢?是不是可以考虑建立一个长链接-短链接的key-value表,将所有的长链接和对应的短链接都存入其中,这样一来就实现了长短链接一一对应的了。但是想法是美好的,现实是不行的,原因在于,将所有的长链接-短链接对存入这样的表中,本身就需要耗费大量的存储空间,相对于生僻链接可能会对应多条短链接浪费的那点空间,这样做显然就得不偿失了。
Q:短链接使用301跳转还是302跳转
A:这里啰嗦一下301和302的跳转在短链接服务使用场景下的区别:用户第一次访问某个短链接后,如果服务器返回301状态码,则这个用户在后续多次访问统一短链接,浏览器会直接请求跳转地址,而不是短链接地址,这样一来服务器端就无法收到用户的请求。如果服务器返回302状态码,且告知浏览器不缓存短链接请求,那么用户每次访问短链接,都会先去短链接服务端取回长链接地址,然后在跳转。从语义上来说,301跳转更为合适,因为是永久跳转,不会每次都访问服务端,还可以减小服务端压力。但如果使用301跳转,服务端就无法精确搜集用户的访问行为了。相反302跳转会导致服务端压力增大,但服务端此时就可精确搜集用户的访问行为。基于用户的访问行为,可以做一些分析,得出一些有意思的结论。比如可以根据用户IP地址得出用户区域分布情况,根据User-Agent消息头分析出用户使用不同的操作系统以及浏览器比例等等。
参考
https://www.zhihu.com/question/29270034/answer/46446911
http://blog.csdn.net/xyz_lmn/article/details/8057270
http://blog.csdn.net/beiyeqingteng/article/details/7706010
文章来源于互联网:短链接原理分析
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.shuli.cc/?p=17007,转载请注明出处。

评论0