1 引言
我觉得数据流与框架的关系,有点像网络与人的关系。
在网络诞生前,人与人之间连接点较少,大部分消息都是通过人与人之间传递,虽然信息整体性不强,但信息在局部非常完备:当你想开一家门面,找到经验丰富的经理人,可以一手包办完。
网络诞生后,如果想通过纯网络的方式,学习如何开门面,如果不是对网络很熟悉,一时半会也难以学习到全套流程。
数据流对框架来说,就像网络对人一样,总是存在着模块功能的完备性与项目整体性的博弈。
全局性强了,对整体性强要求的项目(频繁交互数据)友好,顺便利于测试,因为不利于测试的 UI 与数据关系被抽离开了。
局部性强了,对弱关联的项目友好,这样任何模块都能不依赖全局数据,自己完成所有功能。
对数据流的研究,大多集中于 “优化在某些框架的用法” “基于场景改良” “优化全局与局部数据流间关系” “函数式与面向对象之争” “对输入抽象” “数据格式转换” 这几方面。这里面参杂着统一与分离,类比到网络与人,也许最终只有人脑搬到网络中,才可以达到最终状态。
虚的就说这么多,本篇讲的是 《框架实现》,我们先钻到细节里。
3 精读 dob 框架实现
dob 是个类似 mobx 的框架,实现思路都很类似,如果难以读懂 mobx 的源码,可以先参考 dob 的实现原理。
抽丝剥茧,实现依赖追踪
MVVM 思路中,依赖追踪是核心。
dob 中
observe类似 mobx 的autorun,是使用频率最高的依赖监听工具。
写作时,已经有许多文章将 vue 源码翻来覆去研究过了,因此这里就不长篇大论 MVVM 原理了。
依赖追踪分为两部分,分别是 依赖收集 与 触发回调,如果把这两个功能合起来,就是 observe 函数,分开的话,就是较为底层的 Reaction:
Reaction 双管齐下,一边监听用到了哪些变量,另一边在这些变量改变后,执行回调函数。Observe 利用 Reaction 实现(简化版):
function observe(callback) {
const reaction = new Reaction(() => {
reaction.track(callback)
})
reaction.run()
}reaction.run() 在初始化就执行 new Reaction 的回调,而这个回调又恰好执行 reaction.track(callback)。所以 callback 函数中用到的变量被记录了下来,当变量更改时,会触发 new Reaction 的回调,又重新收集一轮依赖,同时执行了 callback。
这样就实现了回调函数用到的变量被改变后,重新执行这个回调函数,这就是 observe。
为什么依赖追踪只支持同步函数
依赖收集无法得到触发时的环境信息。
依赖收集由 getter、setter 完成,但触发时,却无法定位触发代码位于哪个函数中,所以为了依赖追踪(即变量与函数绑定),需要定义一个全局的变量标示当前执行函数,当各依赖收集函数执行没有交叉时,可以正常运作:
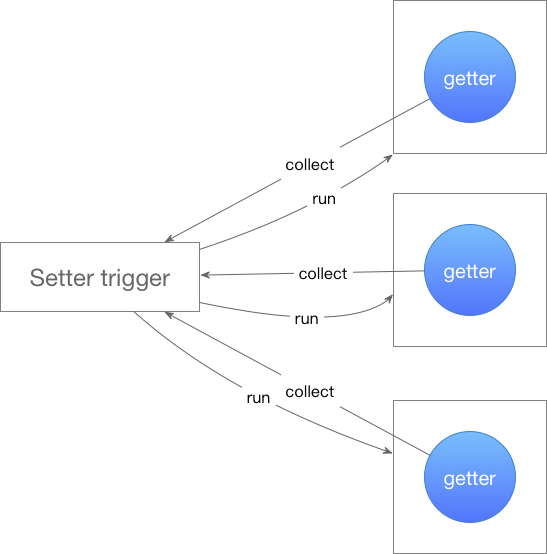
上图右侧白色方块是函数体,getter 表示其中访问到某个变量的 getter,经由依赖收集后,变量被修改时,左侧控制器会重新调用其所在的函数。
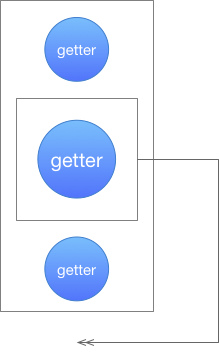
但是,当函数嵌套函数时,就会出现异常:
由于采用全局变量标记法,当回调函数嵌套起来时,当内层函数执行完后,实际作用域已回到了外层,但依赖收集无法获取这个堆栈改变事件,导致后续 getter 都会误绑定到内层函数。
异步(回调)也是同理,虽然写在一个函数体内,但执行的堆栈却不同,因此无法实现正确的依赖收集。
所以需要一些办法,将嵌套的函数放在外层函数执行完毕后,再执行:
换成代码描述如下:
observe(()=>{
console.log(1)
observe(()=>{
console.log(2)
})
console.log(3)
})
// 需要输出 1,3,2当然这不是简单 setTimeout 异步控制就可以,因为依赖收集是同步的,我们要在同步基础上,实现函数执行顺序的变换。
我们可以逐层分解,在每一层执行时,子元素如果是 observe,就会临时放到队列里并跳过,在父 observe 执行完毕后,检查并执行队列,两层嵌套时执行逻辑如下图所示:
这些努力,就是为了保证在同步执行时,所有 getter 都能绑定到正确的回调函数。
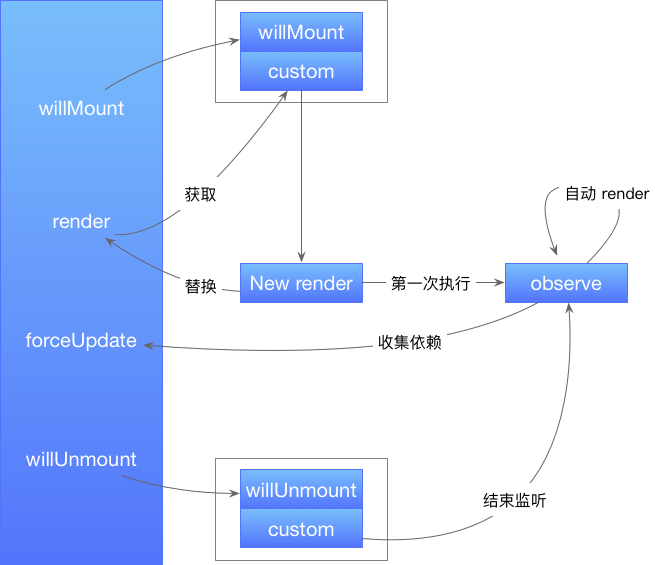
如何结合 React
observe如何到render
observe 可以类比到 React 的 render,它们都具有相同的特征:是同步函数,同时 observe 的运行机制也符合了 render 函数的需求,不是吗?
如果将 observe 用到 react render 函数,当任何 render 函数使用到的变量发生改动,对应的 render 函数就会重新执行,实现 UI 刷新。
要实现结合,用到两个小技巧:聚合生命周期、替换 render 函数,用图才能解释清楚:
以上是简化版,正式版本使用 reaction 实现,可以更清晰的区分依赖收集与 rerender 阶段。
如何避免在 view 中随意修改变量
为了使用起来具有更好的可维护性,需要限制依赖追踪的功能,使值不能再随意的修改。可见,强大的功能,不代表在数据流场景的高可用性,恰当的约束反而会更好。
因此引入 Action 概念,在 Action 中执行的变量修改,不仅会将多次修改聚合成一次 render,而且不在 Action 中的变量修改会抛出异常。
Action 类似进栈出栈,当栈深度不为 0 时,进行的任何的变量修改,拦截到后就可以抛出异常了。
有层次的实现 Debug
一层一层功能逐渐冒泡。
调试功能,在依赖追踪、与 react 结合这一层都需要做,怎样分工配合才能保证功能不冗余,且具有良好的拓展性呢?
数据流框架的 Debug 分为数据层和 UI 层,顺序是 dob 核心记录 debug 信息 -> dob-devtools 读取再加工,强化 UI 信息。
在 UI 层不止可以简单的将对象友好展示出来,更可以通过额外信息采集,将 Action 与 UI 元素绑定,让用户找到任意一次 Action 触发时,rerender 了哪些 UI 元素,以及每个 UI 元素分别与哪些 Action 绑定。
由于数据流需要一个 Provider 提供数据源,与 Connect 注入数据,所以可以将所有与数据流绑定的 UI 元素一一映射到 Debug UI,就像一面镜子一样映射:
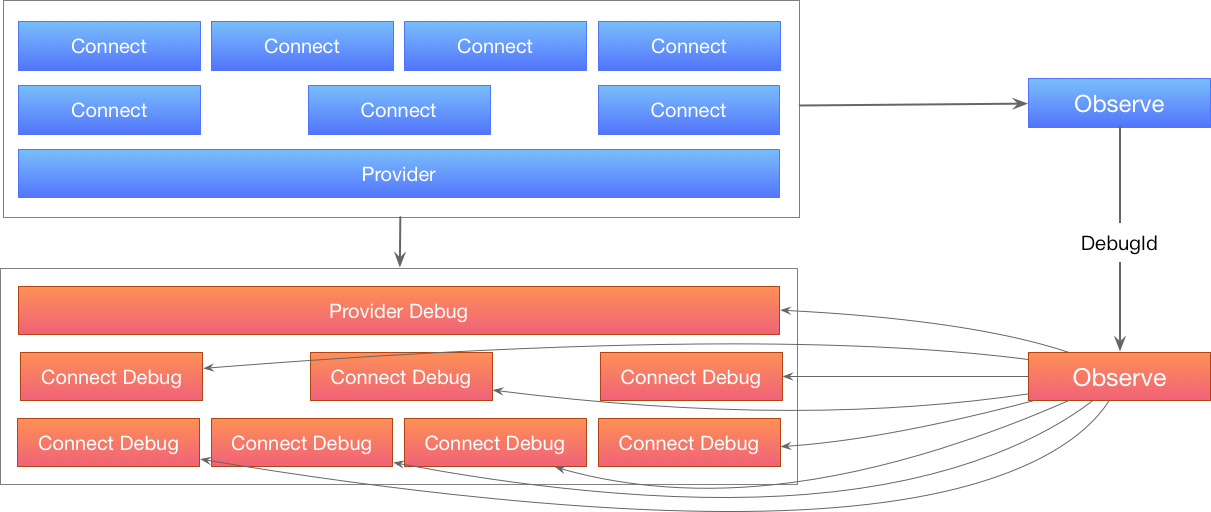
通过 Debug UI,将 debug 信息与 UI 一一对应,实现 dob-react-devtools 的效果。
Debug 功能如何解耦
解耦还能方便许多功能拓展,比如支持 redux。
我得答案是事件。通过精心定义的一系列事件,制造出一个具有生命周期的工具库!
在所有 getter setter 节点抛出相关信息,Debug 端订阅这些事件,找到对自己有用的,记录下来。例如:
event.on("get", info => {
// 不在调试模式
if (!globalState.useDebug) {
return
}
// 记录调用堆栈..
})Dob 目前支持这几种事件钩子:
- get: 任何数据发生了 getter。
- set: 任何数据发生了 setter。
- deleteProperty: 任何数据的 key 被移除时。
- runInAction: 调用了 Action。
- startBatch: 任意 Action 入栈。
- endBatch: 任意 Action 出栈。
并且在关键生命周期节点,还要遵守调用顺序,比如以下是 Action 触发后,到触发 observe 的顺序:
startBatch -> debugInAction -> ...multiple nested startBatch and endBatch -> debugOutAction -> reaction -> observe
如果未开启 debug,执行顺序简化为:
startBatch -> ...multiple nested startBatch and endBatch -> reaction -> observe
订阅了这些事件,可以完成类似 redux-dev-tools 的功能。
2 精读 dob 框架使用
使用 redux 时,很多时候是傻傻分不清要不要将结构化数据拍平,再分别订阅,或者分不清订阅后数据处理应该放在组件上还是全局。这是因为 redux 破坏了 react 分形设计,在 最近的一次讨论记录 有说到。而许多基于 redux 的分形方案都是 “伪” 分形的,偷偷利用 replaceReducer 做一些动态 reducer 注册,再绑定到全局。
讨论理想数据流方案比较痛苦,而且引言里说到,很多业务场景下收益也不大,所以可以考虑结合工程化思维解决,将组件类型区分开,分为普通组件与业务组件,普通组件不使用数据流,业务组件绑定全局数据流,可以避免纠结。
Store 如何管理
使用 Mobx 时,文档告诉我们它具有依赖追踪、监听等许多能力,但没有好的实践例子做指导,看完了 todoMvc 觉得学完了 90%,在项目中实践后发现无从下手。
所谓最佳实践,是基于某种约定或约束,让代码可读性、可维护性更好的方案。约定是活的,不遵守也没事,约束是死的,不遵守就无法运行。约束大部分由框架提供,比如开启严格模式后,禁止在 Action 外修改变量。然而纠结最多的地方还是在约定上,我在写 dob 框架前后,总结出了一套使用约定,可能仅对这种响应式数据流管用。
使用数据流,第一要做的事情就是管理数据,要解决 Store 放在哪,怎么放的问题。其实还有个前置条件:要不要用 Store 的问题。
要不要用 store
首先,最简单的组件肯定不需要用数据流。那么组件复杂时,如果数据流本身具有分形功能,那么可用可不用。所谓具有分形功能的数据流,是贴着 react 分形功能,将其包装成任具有分形能力的组件:
import { combineStores, observable, inject, observe } from 'dob'
import { Connect } from 'dob-react'
@observable
class Store { name = 123 }
class Action {
@inject(Store) store: Store
changeName = () => { this.store.name = 456 }
}
const stores = combineStores({ Store, Action })
@Connect(stores)
class App extends React.Component<typeof stores, any> {
render() {
return <div onClick={this.props.Action.changeName}>{this.props.Store.name}</div>
}
}
ReactDOM.render(<App /> , document.getElementById('react-dom'))dob 就是这样的框架,上面例子中,点击文字可以触发刷新,即便根 dom 节点没有 Provider。这意味着这个组件不论放到任何环境,都可以独立运行,成为任何项目中的一部分。这种组件虽然用了数据流,但是和普通 React 组件完全无区别,可以放心使用。
如果是伪分形的数据流,可能在 ReactDOM.render 需要特定的 Provider 配合才可使用,那么这个组件就不具备可迁移能力。如果别人不幸安装了这种组件,就需要在项目根目录安装一个全家桶。
问:虽然数据流+组件具备完全分形能力,但若此组件对 props 有响应式要求,那还是有对该数据流框架的隐形依赖。
答:是的,如果组件要求接收的 props 是 observable 化的,以便在其变化时自动 rerender,那当某个环境传递了普通 props,这个组件的部分功能将失效。其实 props 属于 react 的通用连接桥梁,因此组件只应该依赖普通对象的 props,内部可以再对其 observable 化,以具备完备的可迁移能力。
怎么用 store
React 虽然可以完全模块化,但实际项目中模块一定分为通用组件与业务组件,页面模块也可以当作业务组件。复杂的网站由数据驱动比较好,既然是数据驱动,那么可以将业务组件与数据的连接移到顶层管理,一般通过页面顶层包裹 Provider 实现:
import { combineStores, observable, inject, observe } from 'dob'
import { Connect } from 'dob-react'
@observable
class Store { name = 123 }
class Action {
@inject(Store) store: Store
changeName = () => { this.store.name = 456 }
}
const stores = combineStores({ Store, Action })
ReactDOM.render(
<Provider {...store}>
<App />
</Provider>
, document.getElementById('react-dom'))本质上只是改变了 Store 定义的位置,而组件使用方式依然不变:
@Connect
class App extends React.Component<typeof stores, any> {
render() {
return <div onClick={this.props.Action.changeName}>{this.props.Store.name}</div>
}
}有一个区别是 @Connect 不需要带参数了,因为如果全局注册了 Provider,会默认透传到 Connect 中。与分形相反,这种设计会导致组件无法迁移到其他项目单独运行,但好处是可以在本项目中任意移动。
分形的组件对结构强依赖,只要给定需要的 props 就可以完成功能,而全局数据流的组件几乎可以完全不依赖结构,所有 props 都从全局 store 获取。
其实说到这里,可以发现这两点是难以合二为一的,我们可以预先将组件分为业务耦合与非业务耦合两种,让业务耦合的组件依赖全局数据流,让非业务耦合组件保持分形能力。
如果有更好的 Store 管理方式,可以在我的 github 和 知乎 深入聊聊。
每个组件都要 Connect 吗
对于 Mvvm 思想的库,Connect 概念不仅仅在于注入数据(与 redux 不同),还会监听数据的变化触发 rerender。那么每个组件需要 Connect 吗?
从数据流功能来说,没有用到数据流的组件当然不需要 Connect,但业务组件保持着未来不确定性(业务不确定),所以保持每个业务组件的 Connect 便于后期维护。
而且 Connect 可能还会做其他优化工作,比如 dob 的 Connect 不仅会注入数据,完成组件自动 render,还会保证组件的 PureRender,如果对 dob 原理感兴趣,可以阅读 精读《dob – 框架实现》。
其实个议题只是非常微小的点,不过现实就是讽刺的,很多时候多会纠结在这种小点子上,所以单独花费篇幅说几句。
数据流是否要扁平化
Store 扁平化有很大原因是 js 对 immutable 支持力度不够,导致对深层数据修改非常麻烦导致的,虽然 immutable.js 这类库可以通过字符串快速操作,但这种使用方式必然会被不断发展的前端浪潮所淹没,我们不可能看到 js 标准推荐我们使用字符串访问对象属性。
通过字符串访问对象属性,和 lodash 的 _.get 类似,不过对于安全访问属性,也已经有 proposal-optional-chaining 的提案在语法层面解决,同样 immutable 的便捷操作也需要一种标准方式完成。实际上不用等待另一个提案,利用 js 现有能力就可以模拟原生 immutable 支持的效果。
dob-redux 可以通过类似 this.store.articles.push(article) 的 mutable 写法,实现与 react-redux 的对接,内部自然做掉了类似 immutable.set 的事情,感兴趣可以读读我的这篇文章:Redux 使用可变数据结构,介绍了这个黑魔法的实现原理。
有点扯远了,那么数据流扁平化本质解决的是数据格式规范问题。比如 normalizr 就是一种标准数据规范的推进,很多时候我们都将冗余、或者错误归类的数据存入 Store,那维护性自然比较差,Redux 推崇的应当是正确的数据格式化,而不是一昧追求扁平化。
对于前端数据流很薄的场景,也不是随便处理数据就完事了。还有许多事可做,比如使用 node 微服务对后端数据标准化、封装一些标准格式处理组件,把很薄的数据做成零厚度,业务代码可以对简单的数据流完全无感知等等。
异步与副作用
Redux 自然而然用 action 隔离了副作用与异步,那在只有 action 的 Mvvm 开发模式中,异步需要如何隔离?Mvvm 真的完美解决了 Redux 避而远之的异步问题吗?
在使用 dob 框架时,异步后赋值需要非常小心:
@Action async getUserInfo() {
const userInfo = await fetchUser()
this.store.user.data = userInfo // 严格模式下将会报错,因为脱离了 Action 作用域。
}原因是 await 只是假装用同步写异步,当一个 await 开始时,当前函数的栈已经退出,因此后续代码都不在一个 Action 中,所以一般的解法是显示申明 Action 的显示申明大法:
@Action async getUserInfo() {
const userInfo = await fetchUser()
Action(() => {
this.store.user.data = userInfo
})
}这说明了异步需要当心!Redux 将异步隔离到 Reducer 之外很正确,只要涉及到数据流变化的操作是同步的,外面 Action 怎么千奇百怪,Reducer 都可以高枕无忧。
其实 redux 的做法与下面代码类似:
@Action async getUserInfo() { // 类 redux action
const userInfo = await fetchUser()
this.setUserInfo(userInfo)
}
@Action async setUserInfo(userInfo) { // 类 redux reduer
this.store.user.data = userInfo
}所以这是 dob 中对异步的另一种处理方法,称作隔离大法吧。所以在响应式框架中,显示申明大法与隔离大法都可以解决异步问题,代码也显得更加灵活。
请求自动重发
响应式框架的另一个好处在于可以自动触发,比如自动触发请求、自动触发操作等等。
比如我们希望当请求参数改变时,可以自动重发,一般的,在 react 中需要这么申明:
componentWillMount() {
this.fetch({ url: this.props.url, userName: this.props.userName })
}
componentWillReceiveProps(nextProps) {
if (
nextProps.url !== this.props.url ||
nextProps.userName !== this.props.userName
) {
this.fetch({ url: nextProps.url, userName: nextProps.userName })
}
}在 dob 这类框架中,以下代码的功能是等价的:
import { observe } from 'dob'
componentWillMount() {
this.signal = observe(() => {
this.fetch({ url: this.props.url, userName: this.props.userName })
})
}其神奇地方在于,observe 回调函数内用到的变量(observable 后的变量)改变时,会重新执行此回调函数。而 componentWillReceiveProps 内做的判断,其实是利用 react 的生命周期手工监听变量是否改变,如果改变了就触发请求函数,然而这一系列操作都可以让 observe 函数代劳。
observe 有点像更自动化的 addEventListener:
document.addEventListener('someThingChanged', this.fetch)所以组件销毁时不要忘了取消监听:
this.signal.unobserve()最近我们团队也在探索如何更方便的利用这一特性,正在考虑实现一个自动请求库,如果有好的建议,也非常欢迎一起交流。
类型推导
如果你在使用 redux,可以参考 你所不知道的 Typescript 与 Redux 类型优化 优化 typescript 下 redux 类型的推导,如果使用 dob 或 mobx 之类的框架,类型推导就更简单了:
import { combineStores, Connect } from 'dob'
const stores = combineStores({ Store, Action })
@Connect
class Component extends React.PureComponent<typeof stores, any> {
render() {
this.props.Store // 几行代码便获得了完整类型支持
}
}这都得益于响应式数据流是基于面向对象方式操作,可以自然的推导出类型。
Store 之间如何引用
复杂的数据流必然存在 Store 与 Action 之间相互引用,比较推荐依赖注入的方式解决,这也是 dob 推崇的良好实践之一。
当然依赖注入不能滥用,比如不要存在循环依赖,虽然手握灵活的语法,但在下手写代码之前,需要对数据流有一套较为完整的规划,比如简单的用户、文章、评论场景,我们可以这么设计数据流:
分别建立 UserStore ArticleStore ReplyStore:
import { inject } from 'dob'
class UserStore {
users
}
class ReplyStore {
@inject(UserStore) userStore: UserStore
replys // each.user
}
class ArticleStore {
@inject(UserStore) userStore: UserStore
@inject(ReplyStore) replyStore: ReplyStore
articles // each.replys each.user
}每个评论都涉及到用户信息,所以 ReplyStore 注入了 UserStore,每个文章都包含作者与评论信息,所以 ArticleStore 注入了 UserStore 与 ReplyStore,可以看出 Store 之间依赖关系应当是树形,而不是环形。
最终 Action 对 Store 的操作也是通过注入来完成,而由于 Store 之间已经注入完了,Action 可以只操作对应的 Store,必要的时候再注入额外 Store,而且也不会存在循环依赖:
class UserAction {
@inject(UserStore) userStore: UserStore
}
class ReplyAction {
@inject(ReplyStore) replyStore: ReplyStore
}
class ArticleAction {
@inject(ArticleStore) articleStore: ArticleStore
}最后,不建议在局部 Store 注入全局 Store,或者局部 Action 注入全局 Store,因为这会破坏局部数据流的分形特点,切记保证非业务组件的独立性,把全局绑定交给业务组件处理。
Action 的错误处理
比较优雅的方式,是编写类级别的装饰器,统一捕获 Action 的异常并抛出:
const errorCatch = (errorHandler?: (error?: Error) => void) => (target: any) => {
Object.getOwnPropertyNames(target.prototype).forEach(key => {
const func = target.prototype[key]
target.prototype[key] = async (...args: any[]) => {
try {
await func.apply(this, args)
} catch (error) {
errorHandler && errorHandler(error)
}
}
})
return target
}
const myErrorCatch = errorCatch(error => {
// 上报异常信息 error
})
@myErrorCatch
class ArticleAction {
@inject(ArticleStore) articleStore: ArticleStore
}当任意步骤触发异常,await 之后的代码将停止执行,并将异常上报到前端监控平台,比如我们内部的 clue 系统。关于异常处理更多信息,可以访问我较早的一篇文章:Callback Promise Generator Async-Await 和异常处理的演进。
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.shuli.cc/?p=17585,转载请注明出处。

评论0