1. 引言
本周精读的文章是 regexp-features-regular-expressions。
这篇文章介绍了 ES2018 正则支持的几个重要特性:
- Lookbehind assertions – 后行断言
- Named capture groups – 命名捕获组
- s (dotAll) Flag – . 匹配任意字符
- Unicode property escapes – Unicode 属性转义
2. 概述
还在用下标匹配内容吗?匹配任意字符只有 [\w\W] 吗?现在正则有更简化的写法了,事实上正则正在变得更加易用,是时候更新对正则的认知了。
2.1. Lookbehind assertions
完整的断言定义分为:正/负向断言 与 先/后行断言 的笛卡尔积组合,在 ES2018 之前仅支持先行断言,现在终于支持了后行断言。
解释一下这四种断言:
正向先行断言 (?=...) 表示之后的字符串能匹配 pattern。
const re = /Item(?= 10)/;
console.log(re.exec("Item"));
// → null
console.log(re.exec("Item5"));
// → null
console.log(re.exec("Item 5"));
// → null
console.log(re.exec("Item 10"));
// → ["Item", index: 0, input: "Item 10", groups: undefined]负向先行断言 (?!...) 表示之后的字符串不能匹配 pattern。
const re = /Red(?!head)/;
console.log(re.exec("Redhead"));
// → null
console.log(re.exec("Redberry"));
// → ["Red", index: 0, input: "Redberry", groups: undefined]
console.log(re.exec("Redjay"));
// → ["Red", index: 0, input: "Redjay", groups: undefined]
console.log(re.exec("Red"));
// → ["Red", index: 0, input: "Red", groups: undefined]在 ES2018 后,又支持了两种新的断言方式:
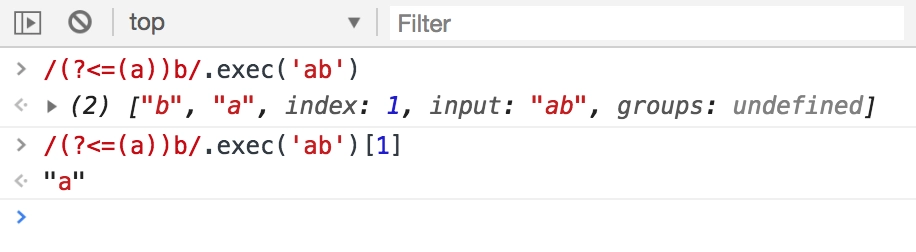
正向后行断言 (?<=...) 表示之前的字符串能匹配 pattern。
先行时字符串放前面,pattern 放后面;后行时字符串放后端,pattern 放前面。先行匹配以什么结尾,后行匹配以什么开头。
const re = /(?<=€)\d+(\.\d*)?/;
console.log(re.exec("199"));
// → null
console.log(re.exec("$199"));
// → null
console.log(re.exec("€199"));
// → ["199", undefined, index: 1, input: "€199", groups: undefined]负向后行断言 (?<!...) 表示之前的字符串不能匹配 pattern。
注:下面的例子表示 meters 之前 不能匹配 三个数字。
const re = /(?<!\d{3}) meters/;
console.log(re.exec("10 meters"));
// → [" meters", index: 2, input: "10 meters", groups: undefined]
console.log(re.exec("100 meters"));
// → null文中给了一个稍复杂的例子,结合了 正向后行断言 与 负向后行断言:
注:下面的例子表示 meters 之前 能匹配 两个数字,且 之前 不能匹配 数字 35.
const re = /(?<=\d{2})(?<!35) meters/;
console.log(re.exec("35 meters"));
// → null
console.log(re.exec("meters"));
// → null
console.log(re.exec("4 meters"));
// → null
console.log(re.exec("14 meters"));
// → ["meters", index: 2, input: "14 meters", groups: undefined]2.2. Named Capture Groups
命名捕获组可以给正则捕获的内容命名,比起下标来说更可读。
其语法是 ?<name>:
const re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
const [match, year, month, day] = re.exec("2020-03-04");
console.log(match); // → 2020-03-04
console.log(year); // → 2020
console.log(month); // → 03
console.log(day); // → 04也可以在正则表达式中,通过下标 \1 直接使用之前的捕获组,比如:
解释一下,
\1代表(\w\w)匹配的内容而非(\w\w)本身,所以当(\w\w)匹配了'ab'后,\1表示的就是对'ab'的匹配了。
console.log(/(\w\w)\1/.test("abab")); // → true
// if the last two letters are not the same
// as the first two, the match will fail
console.log(/(\w\w)\1/.test("abcd")); // → false对于命名捕获组,可以通过 \k<name> 的语法访问,而不需要通过 \1 这种下标:
下标和命名可以同时使用。
const re = /\b(?<dup>\w+)\s+\k<dup>\b/;
const match = re.exec("I'm not lazy, I'm on on energy saving mode");
console.log(match.index); // → 18
console.log(match[0]); // → on on2.3. s (dotAll) Flag
虽然正则中 . 可以匹配任何字符,但却无法匹配换行符。因此聪明的开发者们用 [\w\W] 巧妙的解决了这个问题。
然而这终究是个设计缺陷,在 ES2018 支持了 /s 模式,这个模式下,. 等价于 [\w\W]:
console.log(/./s.test("\n")); // → true
console.log(/./s.test("\r")); // → true2.4. Unicode Property Escapes
正则支持了更强大的 Unicode 匹配方式。在 /u 模式下,可以用 \p{Number} 匹配所有数字:
u 修饰符可以识别所有大于 0xFFFF 的 Unicode 字符。
const regex = /^\p{Number}+$/u;
regex.test("²³¹¼½¾"); // true
regex.test("㉛㉜㉝"); // true
regex.test("ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩⅪⅫ"); // true\p{Alphabetic} 可以匹配所有 Alphabetic 元素,包括汉字、字母等:
const str = "漢";
console.log(/\p{Alphabetic}/u.test(str)); // → true
// the \w shorthand cannot match 漢
console.log(/\w/u.test(str)); // → false终于有简便的方式匹配汉字了。
2.5. 兼容表
可以到 原文 查看兼容表,总体上只有 Chrome 与 Safari 支持,Firefox 与 Edge 都不支持。所以大型项目使用要再等几年。
3. 精读
文中列举的四个新特性是 ES2018 加入到正则中的。但正如兼容表所示,这些特性基本还都不能用,所以不如我们再温习一下 ES6 对正则的改进,找一找与 ES2018 正则变化的结合点。
3.1. RegExp 构造函数优化
当 RegExp 构造函数第一个参数是正则表达式时,允许指定第二个参数 – 修饰符(ES5 会报错):
new RegExp(/book(?=s)/giu, "iu");不痛不痒的优化,,毕竟大部分时间构造函数不会这么用。
3.2. 字符串的正则方法
将字符串的 match()、replace()、search、split 方法内部调用时都指向到 RegExp 的实例方法上,比如
String.prototype.match 指向 RegExp.prototype[Symbol.match]。
也就是正则表达式原本应该由正则实例触发,但现在却支持字符串直接调用(方便)。但执行时其实指向了正则实例对象,让逻辑更为统一。
举个例子:
"abc".match(/abc/g) /
// 内部执行时,等价于
abc /
g[Symbol.match]("abc");3.3. u 修饰符
概述中,Unicode Property Escapes 就是对 u 修饰符的增强,而 u 修饰符是在 ES6 中添加的。
u 修饰符的含义为 “Unicode 模式”,用来正确处理大于 \uFFFF 的 Unicode 字符。
同时 u 修饰符还会改变以下正则表达式的行为:
- 点字符原本支持单字符,但在
u模式下,可以匹配大于0xFFFF的 Unicode 字符。 - 将
\u{61}含义由匹配 61 个u改编为匹配 Unicode 编码为 61 号的字母a。 - 可以正确识别非单字符 Unicode 字符的量词匹配。
\S可以正确识别 Unicode 字符。u模式下,[a-z]还能识别 Unicode 编码不同,但是字型很近的字母,比如\u212A表示的另一个K。
基本上,在 u 修饰符模式下,所有 Unicode 字符都可以被正确解读,而在 ES2018,又新增了一些 u 模式的匹配集合来匹配一些常见的字符,比如 \p{Number} 来匹配 ¼。
3.4. y 修饰符
y 修饰符是 “粘连”(sticky)修饰符。
y 类似 g 修饰符,都是全局匹配,也就是从上次成功匹配位置开始,继续匹配。y 的区别是,必须是上一次匹配成功后的下一个位置就立即匹配才算成功。
比如:
/a+/g.exec("aaa_aa_a"); // ["aaa"]3.5. flags
通过 flags 属性拿到修饰符:
const regex = /[a-z]*/gu;
regex.flags; // 'gu'4. 总结
本周精读借着 regexp-features-regular-expressions 这篇文章,一起理解了 ES2018 添加的正则新特性,又顺藤摸瓜的整理了 ES6 对正则做的增强。
如果你擅长这种扩散式学习方式,不妨再进一步温习一下整个 ES6 引入的新特性,笔者强烈推荐阮一峰老师的 ECMAScript 6 入门 一书。
ES2018 引入的特性还太新,单在对 ES6 特性的使用应该和对 ES3 一样熟练。
如果你身边的小伙伴还对 ES6 特性感到惊讶,请把这篇文章分享给他,防止退化为 “只剩项目经验的 JS 入门者”。
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.shuli.cc/?p=17748,转载请注明出处。

评论0